
Scraping Browser XHR Requests with Python: A Step-by-Step Guide [2024 Guide]
Introduction
Scraping Browser XHR requests can be a great way to gather data from websites and APIs, but it can also be a bit tricky to get started with. Fortunately, Python provides a number of powerful tools that make it easier than ever to scrape data from websites and APIs.
What is a Browser XHR request?
Before we get started, let’s define what a Browser XHR request is. XHR stands for “XMLHttpRequest”, and it’s a standard way for web browsers to communicate with web servers. When a website sends an XHR request, it’s typically asking the server for some data or information. This data can be in a variety of formats, including JSON, XML, or plain text.
Prequesties
- Basic knowledge of the browser developer console
- The latest version of python
- Python Request library ( I will explain how to install these later)
Role of Webbrowser and developer tools in web scraping
To start scraping browser XHR requests, the first thing you’ll need to do is to intercept and analyze these browser XHR requests. This can be done using your web browser itself. Open the Developer Tool of your browser.

To access the Developer Tools on your web browser, simply right-click anywhere on a webpage and select “Inspect” from the menu.
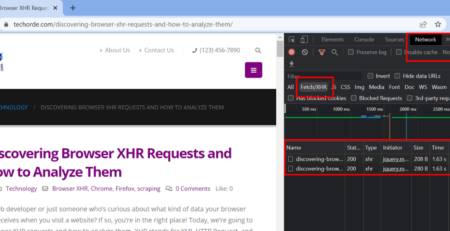
We need to work on the Network tab to intercept and analyze these browser XHR requests. Click on the Network tab and select Fetch/XHR as in the below screenshot.

Now you can reload the page and you can see all the API calls done by the browser to render the webpage. You can start making requests on the website you’re interested in scraping. As you make requests, you’ll see them show up in the Network tab. To see the details of a particular request, simply click on it. You’ll be able to see the request headers, the response headers, and the response body.

Here in this method we are not using selenium or any other framework to scrape web, we are using Request library to call POST/ GET requests to the frondend API endpoint used by browsers and capture the JSON response. We can then save this as a CSV or as JSON data itslef.
Installing Python and required libraries
Now that you know how to intercept and analyze XHR requests, let’s talk about how to scrape them using Python. To do this, we’ll use the Requests library, which is a popular Python library for making HTTP requests.
Installing Python
You need to have Python installed on your computer for this. based on your OS, you can download and install Python from this link https://www.python.org/downloads/
After installing Python, you can run the following code to install PIP(skip this step if PIP is already installed)
python get-pip.py
After installing PIP we need to install the Request library, for this run the following code in your terminal/CMD
pip install requests
Now we have set up our basic requirements to scrape browser XHR requests using Python. Let so some real-world scraping.
Remember always to respect the website’s terms of service and be careful not to overwhelm their servers with too many requests.
Let’s do some real-world data scraping.
Two months back, before writing this blog on Feb 2023, I was in search of a sustainable solution to scrape the web, and I don’t have any thorough programming knowledge as I am from a marketing background.
So what did I do? I asked my secret programming guru, the chat GPT3. And here is how it is done.
Let’s scrape the website https://www.scrapethissite.com/pages/ajax-javascript/#2013
Here on this webpage, Oscar movies are listed based on year. The content is delivered as a JSON payload. 
The above page is listing Oscar Winning Films based on year using AJAX and Javascript. So as you can see the results are loaded upon clicking the Year menu.
Step 1 . Load the page on your web browser
Step 2. Analyze the XHR requests.
To check the XHR requests, open the browser console by right-clicking and selecting inspect element
Step 3. Select the XHR and fetch under the Network tab


Now if you click on each year, you can see the XHR requests populated under the tab, refer to the screenshot below
Now check the Fetch/XHR tab, you can see some juicy informations

- Headers
- Payload
- Response
Lets deep dive into each of these
Headers
XHR (XMLHttpRequest) headers are additional information that can be sent along with an XMLHttpRequest object to provide more context and control over the request being made to a server.
There are several types of XHR headers, including:
- Request headers: These are sent by the client to the server and provide information about the request being made. Examples include the Accept header, which specifies the MIME types that the client can handle, and the Authorization header, which contains authentication credentials.
- Response headers: These are sent by the server in response to the client’s request and provide information about the response being returned. Examples include the Content-Type header, which specifies the MIME type of the response, and the Cache-Control header, which specifies caching behavior.
- Entity headers: These are associated with the entity-body of a request or response, such as the Content-Length header, which specifies the length of the message body.
XHR headers are typically set using the setRequestHeader() method on the XMLHttpRequest object, which takes two arguments: the header’s name and its value. For example, to set the Accept header to “application/json”, you would call xhr.setRequestHeader(“Accept”, “application/json”).
Let’s check the header for the year 2015
General
Request headers
:authority: www.scrapethissite.com :method: GET :path: /pages/ajax-javascript/?ajax=true&year=2015 :scheme: https accept: */* accept-encoding: gzip, deflate, br accept-language: en-IN,en;q=0.5 dnt: 1 referer: https://www.scrapethissite.com/pages/ajax-javascript/ sec-fetch-dest: empty sec-fetch-mode: cors sec-fetch-site: same-origin sec-gpc: 1 user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 x-requested-with: XMLHttpRequest
here the browser is sending a GET request to the endpoint https://www.scrapethissite.com/pages/ajax-javascript/?ajax=true&year=2015 with along with some additional data tagged under Request headers.
Payload
Apart from request headers, the browser is sending some additional data which is available under the payload tab
ajax=true&year=2015
Now when the browser sends the payload to the endpoint URL with the necessary request header, the server will respond with the desired response. And that can be seen under the response tab. and here, in our case for a page load, only one request is sent to the server and the server responds with only one response. In a real case scenario, there will be multiple requests sent to the server based on the complexity of page load( we will look into scrape such a page later )
Here is the response data that we got from the server
[
{
"title": "Argo",
"year": 2012,
"awards": 3,
"nominations": 7,
"best_picture": true
},
{
"title": "Life of Pi",
"year": 2012,
"awards": 4,
"nominations": 11
},
{
"title": "Les Mis\u00e9rables",
"year": 2012,
"awards": 3,
"nominations": 8
},
{
"title": "Lincoln",
"year": 2012,
"awards": 2,
"nominations": 12
},
{
"title": "Django Unchained",
"year": 2012,
"awards": 2,
"nominations": 5
},
{
"title": "Skyfall",
"year": 2012,
"awards": 2,
"nominations": 5
},
{
"title": "Silver Linings Playbook",
"year": 2012,
"awards": 1,
"nominations": 8
},
{
"title": "Zero Dark Thirty",
"year": 2012,
"awards": 1,
"nominations": 5
},
{
"title": "Amour",
"year": 2012,
"awards": 1,
"nominations": 5
},
{
"title": "Anna Karenina",
"year": 2012,
"awards": 1,
"nominations": 4
},
{
"title": "Paperman",
"year": 2012,
"awards": 1,
"nominations": 1
},
{
"title": "Brave",
"year": 2012,
"awards": 1,
"nominations": 1
},
{
"title": "Searching for Sugar Man",
"year": 2012,
"awards": 1,
"nominations": 1
},
{
"title": "Inocente",
"year": 2012,
"awards": 1,
"nominations": 1
},
{
"title": "Curfew",
"year": 2012,
"awards": 1,
"nominations": 1
}
]
As we can see, the response is in JSON format. And this is the desired data that we need to capture into a CSV file.
You can copy this JSON data into some JSON to CSV converter online and convert this JSON response as a CSV file.
But this process is not scalable; what if you have hundreds of JSON files and convert them into CSV? What if you need to crawl all the pages listed under pagination?







Leave a Reply